
摘要:收录:页面被Baiduspider发现、分析过。百度站长平台链接提交工具是通往收录的大门。【索引意义2】新闻源站点(新闻源目录)内的链接,必须先被网页库建索引,才有机会出现在新闻检索中。下面进入正式话题,不会编程,10W+网站链接如何查询收录?方法二:利用百度的查询收录接口【更适合编程来查询】
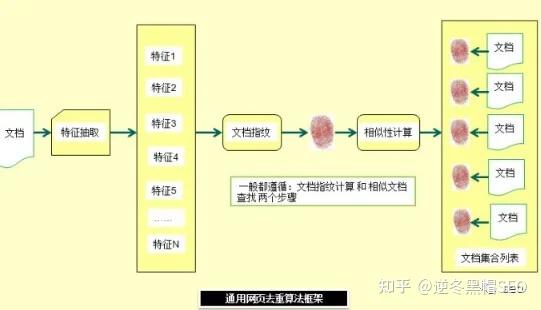
1. 集合和索引简介
1. 集合和索引分别是什么意思?
包含:该页面已被Baiduspider发现并分析。
索引:经过初步分析,Baiduspider觉得有意义,开始建库。
2、集合与索引的关系
包含关系中如何查看网站是否被百度收录,包含后才能建立索引,且包含量大于索引量。 百度站长平台链接提交工具是收录之门。
3.收录和索引的含义(简单介绍,不展开)
【收录意义1】收录是建立索引的前提。 网站需要保持服务器稳定(参考爬虫诊断工具和爬虫异常工具)且机器人正确(《机器人编写及所需使用对应表》),为Baiduspider爬行铺平道路。
【包含意义2】Baiduspider只能处理已经分析过的页面。 面对新旧页面301和移动适配,可以完成收录页面的权重评分和流量切换。
【索引含义1】只有内置索引库的网页才有机会获取流量(网页虽然内置索引库,但获取流量的机会不同,无效索引很难获取流量)。
【索引含义2】新闻源站点(新闻源目录)中的链接必须先被网络数据库索引,才有机会出现在新闻检索中。
关于收录-索引-排名的问题,搜索引擎会有一个门槛。 当您的网页质量达到此阈值时,该页面将被收录并建立索引以进行排名。 您超过此阈值的次数越多,您的排名就越低。 更好。
由于百度近期调整了一些收录评价因素,部分网站的收录速度放缓或减少。 可能需要评估最近产生的链接的收录情况(收录率、收录速度等如何查看网站是否被百度收录,ps。目前一些大网站的收录率可能比较高。好吧,你可以忽略这个,但是了解整体的收录率而网站的阶段性收录率对于网站来说也是必不可少的)。

Sonata、shoulv、seducha 和其他 seo 工具包都对数百个查询开放。 如果您查询更多,您将被收取会员费。 那么陈老SEO教你如何自行查询。 后面也给出了python脚本。 方法查询。
【缺点询价数量有限,部分需要付费】
2. 集合和索引简介
虽然建议使用py或者其他语言批量查询大量集合,但考虑到部分新手可能暂时做不到。 现在让我们进入正式主题。 我不知道如何编程。 如何检查并包含 100,000 多个网站链接?
方法一:使用Locomotive批量查询URL【适合不会编程的同学】
1、利用Locomotive自制的集合查询功能,判断收录页面的特征(是否有百度快照(也可以使用其他特征);快照日期的显示时间,不是所有页面都可能有快照日期)
(1)构造查询URL【构造的URL为【baidu.com不能为https】
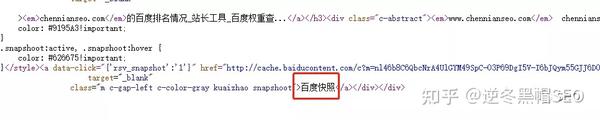
baidu.com/s?wd=http://www.chennianseo.com/seo/200
(2)查询是否包含[包含的项目]
类=“m”>(*)
(3) 捕捉快照时间[快照时间]
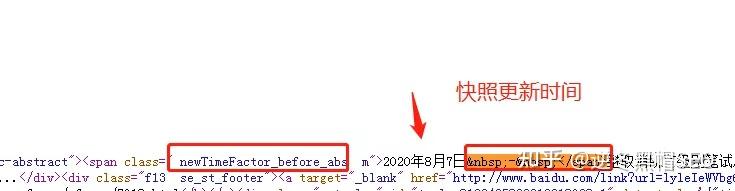
newTimeFactor_before_abs (*) -
(4)设置excel导出
(5)计算查询页面的总收录率。
注:这里推荐使用Locomotive破解版。 主控线程数为2-3个比较合适,不易被ban。 笔者这里尝试了5万个URL查询,比使用python脚本查询稍微慢一些。 如果条件允许的话可以使用。 代理,可以加快爬取速度。 另外,还可以添加cookies和ua。
方法二:使用百度的查询采集接口【比较适合编程查询】
baidu.com/s?wd=http://www.chennianseo.com/seo/200&tn=json
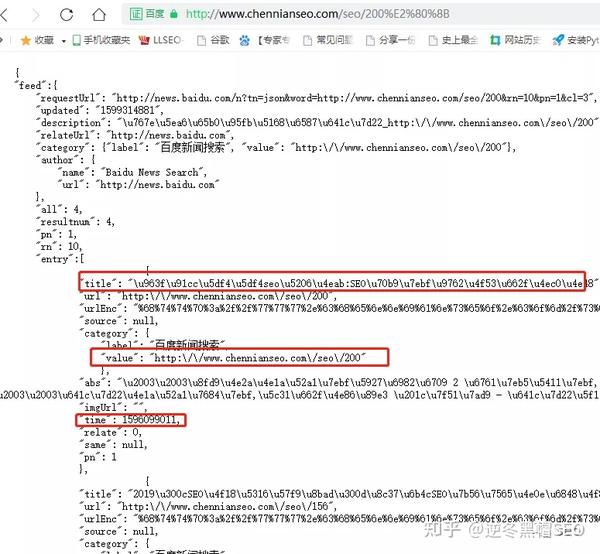
还可以使用接口批量查询,获取百度时间戳,然后使用时间戳时间换算。
使用接口查询的采集精度较高,快照的时间精度也较高。





